The world is getting “smarter” every day, and to keep up with consumer expectations, companies are increasingly using machine learning algorithms to make things easier.
Machine learning is a sub-field of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed.
There are two basic approaches for this: Supervised learning and Unsupervised learning.
What is supervised learning?
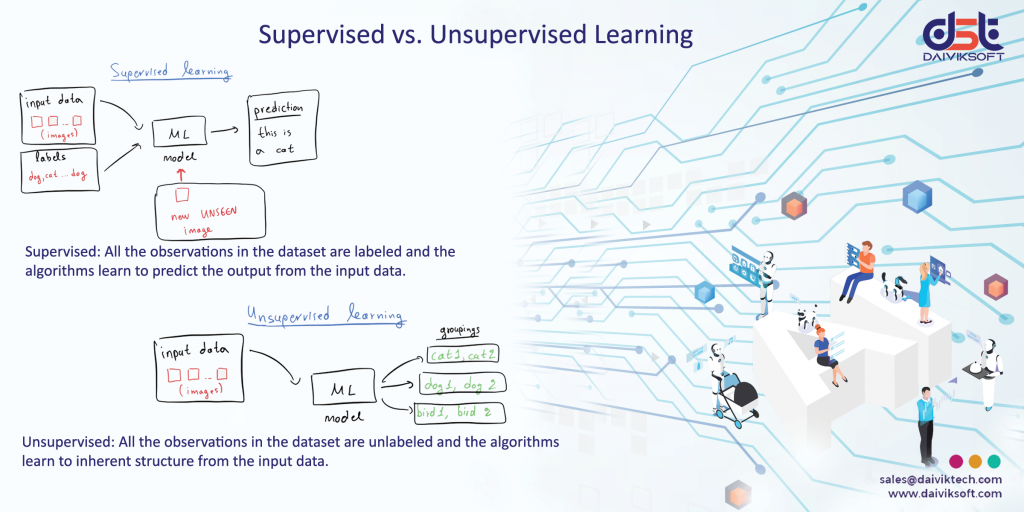
Supervised learning is an approach that’s defined by its use of labelled datasets. These datasets are designed to train or “supervise” algorithms into classifying data or predicting outcomes accurately. Using labelled inputs and outputs, the model can measure its accuracy and learn over time.
Supervised learning can be separated into two types of problems when data mining:
Classification and Regression:
Classification problems use an algorithm to accurately assign test data into specific categories, such as separating apples from oranges. Linear classifiers, support vector machines, decision trees and random forest are all common types of classification algorithms.
Regression is another type of supervised learning method that uses an algorithm to understand the relationship between dependent and independent variables. Some popular regression algorithms are linear regression, logistic regression and polynomial regression.
What is unsupervised learning?
Unsupervised learning uses machine learning algorithms to analyze and cluster unlabeled data sets. These algorithms discover hidden patterns in data without the need for human intervention (hence, they are “unsupervised”).
Unsupervised learning models are used for three main tasks:
Clustering, Association and dimensionality reduction
Clustering is a data mining technique for grouping unlabeled data based on their similarities or differences. This technique is helpful for market segmentation, image compression, etc.
Association is another type of unsupervised learning method that uses different rules to find relationships between variables in a given dataset.
Dimensionality reduction is a learning technique used when the number of features in a given dataset is too high. It reduces the number of data inputs to a manageable size while also preserving the data integrity.
Just as students in a school, every algorithm learns differently. But with the diversity of approaches available, it’s only a matter of picking the best way to help your neural network learn the ropes.